05.1.4: Live Lab: Prepare Data in Different File Formats
Data Acquisition & Formats เพราะข้อมูลไม่ได้มาในรูปแบบเดียวเสมอไป หน้าที่ของ Data Analyst คือการอ่าน “รหัส” ของไฟล์แต่ละประเภทให้ออก เพื่อนำไปสู่การประมวลผลและสร้างรายงานที่แม่นยำ
The Mission: Steps to Discovery
1. Decoding Delimited File Formats
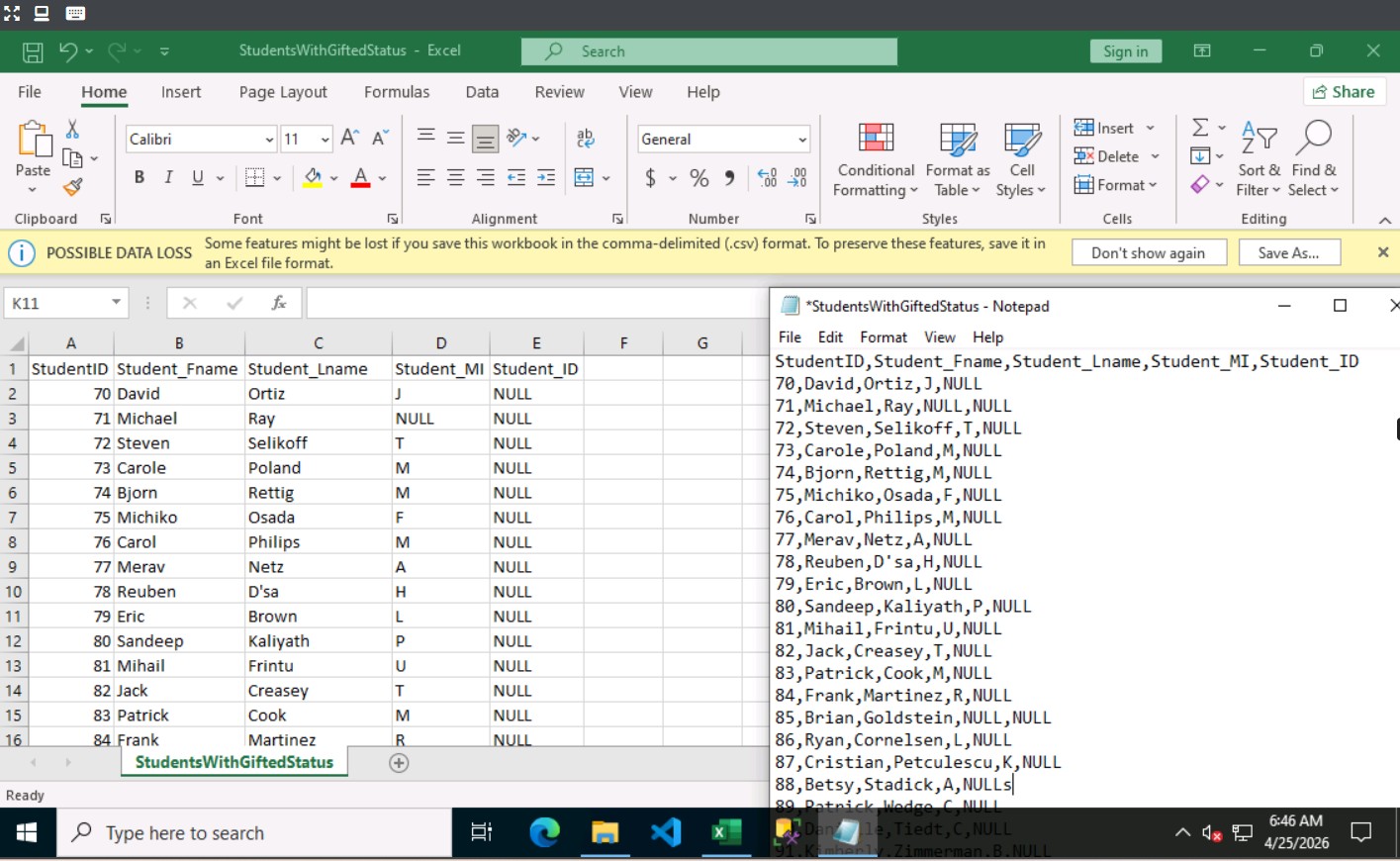 ขั้นตอนสำคัญคือการแยกแยะไฟล์แบบ “มีตัวคั่น” (Delimited) ซึ่งเป็นรูปแบบมาตรฐานในการ Export ข้อมูลจากระบบต่างๆ เราได้เรียนรู้วิธีการระบุตัวคั่นประเภทต่างๆ เช่น:
ขั้นตอนสำคัญคือการแยกแยะไฟล์แบบ “มีตัวคั่น” (Delimited) ซึ่งเป็นรูปแบบมาตรฐานในการ Export ข้อมูลจากระบบต่างๆ เราได้เรียนรู้วิธีการระบุตัวคั่นประเภทต่างๆ เช่น:
- Comma (CSV): รูปแบบที่นิยมที่สุดสำหรับการทำตารางข้อมูล
- Tabs / Semicolons / Pipes (|): ตัวคั่นทางเลือกที่ช่วยลดปัญหาเมื่อข้อมูลในฟิลด์มีเครื่องหมายคอมมาปนอยู่
Insight: การระบุ Delimiter ผิดเพียงจุดเดียว อาจทำให้การ Import ข้อมูลผิดพลาดหรือโครงสร้างข้อมูลบิดเบี้ยว (Misaligned)
2. Inspecting JSON Structures
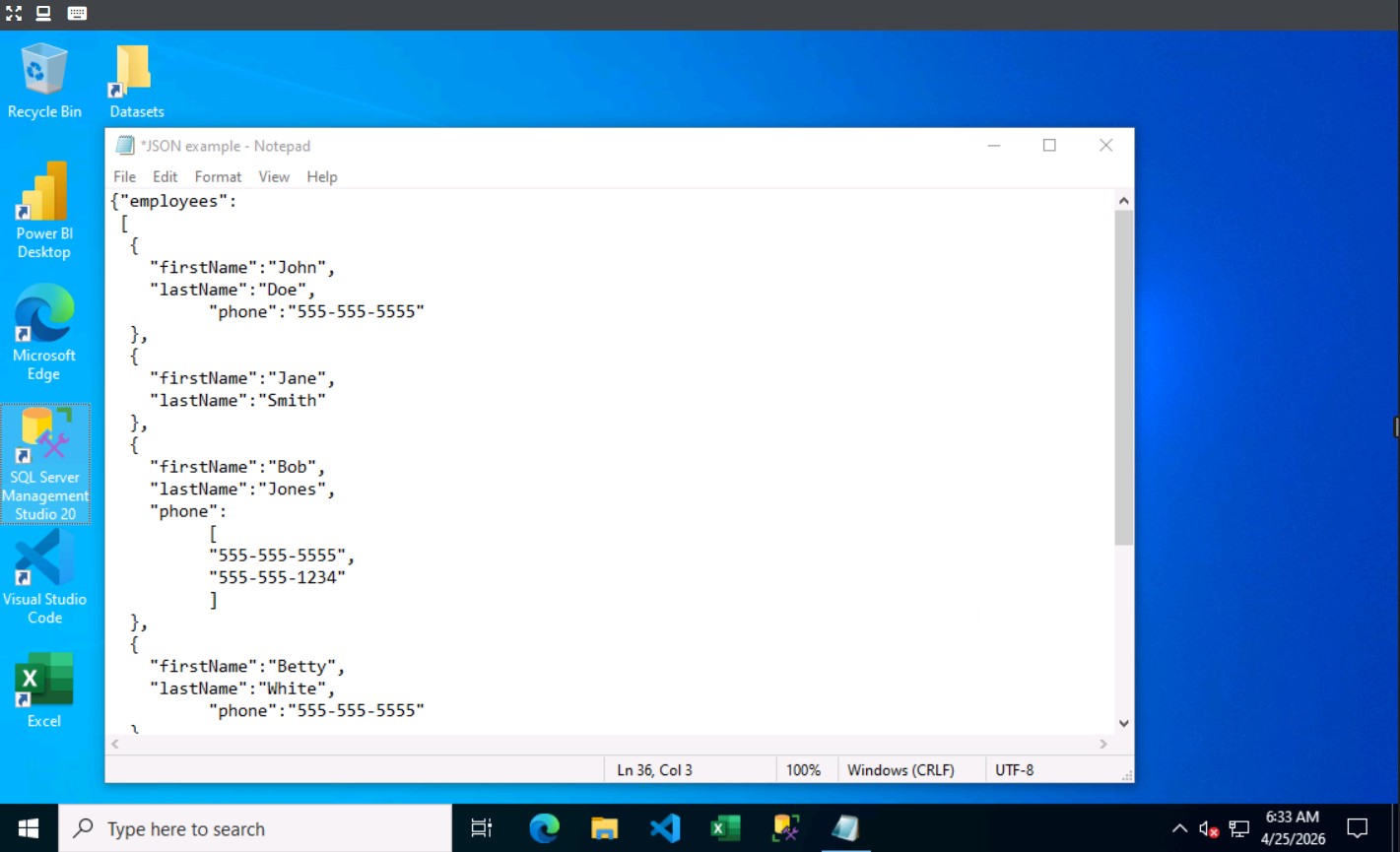 เราได้เจาะลึกไฟล์ JSON (JavaScript Object Notation) ซึ่งเป็นหัวใจของการแลกเปลี่ยนข้อมูลในยุคปัจจุบัน โดยเน้นไปที่ 3 คุณสมบัติหลัก:
เราได้เจาะลึกไฟล์ JSON (JavaScript Object Notation) ซึ่งเป็นหัวใจของการแลกเปลี่ยนข้อมูลในยุคปัจจุบัน โดยเน้นไปที่ 3 คุณสมบัติหลัก:
- การเก็บข้อมูลแบบ Name/Value pairs ที่อ่านง่ายทั้งคนและเครื่อง
- การใช้ Commas แยกชุดข้อมูล และ Square brackets สำหรับเก็บ Arrays
- ความยืดหยุ่นในการเก็บข้อมูลแบบลำดับชั้น (Nested structure)
3. Identifying Data Sources
เราได้จำลองสถานการณ์การเลือกแหล่งข้อมูลให้เหมาะสมกับงาน (Data Acquisition) โดยวิเคราะห์ว่าข้อมูลประเภทใดควรมาจากไฟล์แบนๆ (Flat files) หรือข้อมูลแบบกึ่งโครงสร้าง (Semi-structured) เพื่อประสิทธิภาพสูงสุดในการทำ Analytics
การตรวจสอบโครงสร้าง CSV (Delimiter Identification)
```text EmployeeID,FullName,Department,Salary 101,John Doe,Data Science,85000 102,Jane Smith,AI Engineering,92000